Requirements
This post aims to present the current proposal for the networking layer in Coordicide. The term networking is somehow generic, and it basically refers to all actions taken by the protocol in order to optimally share resources (CPU, bandwidth, storage) between all nodes, while guaranteeing that packets will be eventually delivered to all nodes. More specifically, the goal of this protocol is to address the following requirements:
- Consistency: honest nodes write into their ledger the same set of transactions.
- High utilization: network works at the highest possible throughput, bounded by the resources available rather than the protocol.
- Fairness: nodes get a fair share of throughput depending on their reputation (mana).
- Low delay: the maximum delay needed to deliver honest transactions to all nodes is low.
- Lightweight and scalable: the protocol is able to deal with very large heterogeneous networks.
- Adversarial environment: nodes can make any action to slow down the protocol or to maximize their throughput.
While this is apparently a prohibitive challenge, in the rest of the post we will be presenting our current proposal which, according to our preliminary Python simulations, achieves all the above requirements.
Our proposal
Our proposal is made of three interconnected modules as shown in the figure below.

When incoming transactions arrive to nodes, they will take actions according to these three modules:
- Rate control. First of all, nodes verify whether the issuing node has solved the PoW with enough difficulty. The difficulty depends on the number of transactions recently issued by the same nodes. More details on this mechanism, called Adaptive PoW, can be found in other IOTA Café posts [1][2]. We highlight here that Adaptive PoW is independent of the mana owned by the node. In other words, rate control is used to set an upper bound on the throughput capacity per node in order to avoid bursts of transactions which may lead to Denial of Service attacks. We deal with Sybil protection in the other two modules.
- Rate setting. Inspired by the additive increase multiplicative decrease algorithm successfully implemented in TCP, we let a node increase its transaction generation rate if the network is not congested. In this way, we can efficiently exploit unused resources. An interesting aspect of the rate setting is the back off message: unlike TCP, where a node sends explicit back off notifications to neighbors in case of local congestion, here all nodes have knowledge of the congestion status of the network since transactions are broadcasted. Hence, a node can use this knowledge to properly set its fair share of throughput without the need for an explicit back off message. In case a dishonest node does not apply this self back off, the scheduling module would take care of the scenario, as described below.
- Scheduling. The last module, called scheduling, chooses which transaction in the inbox queue must be gossiped next. The choice of the transaction depends on a certain priority which depends on: (i) mana owned by the issuing node; (ii) the difference between the timestamps of its oldest transaction in the inbox and its latest one being gossiped (we used to refer to this as gap score). This scheduling algorithm guarantees max-min fairness and it is somehow similar to the Weighted Round Robin algorithm.
Simulation results
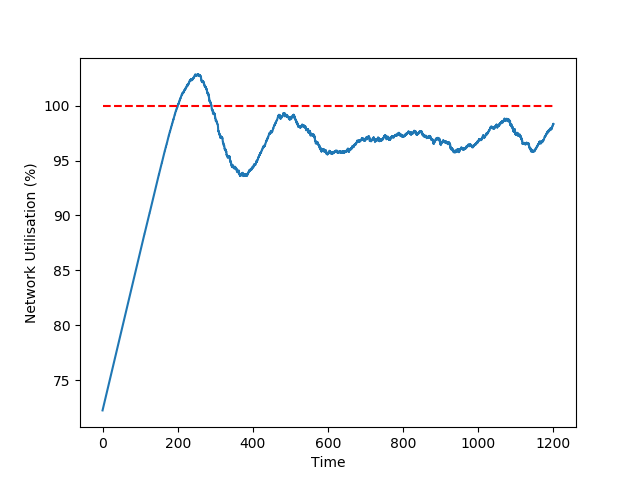
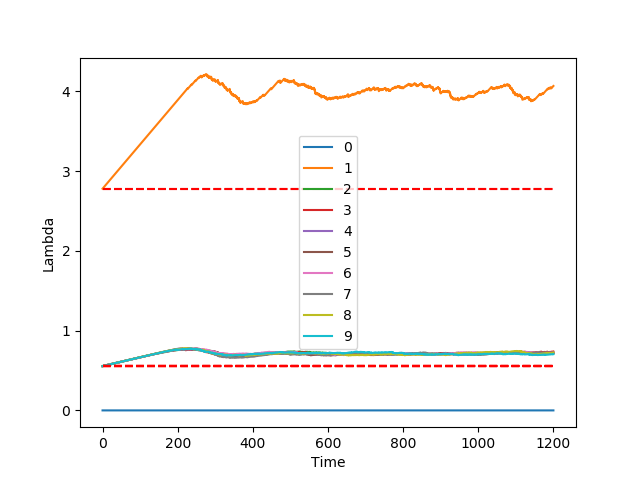
We built a Python simulator to validate the proposed protocol. In the following plots, we simulate a network with 10 nodes where nodes 0 and 1 and reputation 5x larger than any other node in the network. In the simulations, node 0 is not active, while all other nodes try to issue transactions at the maximum throughput they are allowed to.
In the figure on the left side, we plot the network utilization over time: the AIMD protocol guarantees a very high utilization of resources, in our scenario included between 96% and 99%.
In the figure on the right side, we plot the throughput: it is evident that the fairness criterion is guaranteed as node 1 indeed gets around five times more throughput than all other nodes.
Attack analysis
The actions a malicious node can take to harm the network are very limited. First of all, its throughput is bounded by the Adaptive PoW algorithm, hence it cannot indefinitely spam the network. Second, assuming it tries to issue transactions at the maximum throughput allowed by the rate control, the scheduling algorithm would never schedule (hence gossip) its transactions if the time interval is too short in congested periods. In practice, transactions issued in this way will get an arbitrarily large delay before being delivered to all nodes. In order to increase protection against such behaviors which can inflate nodes’ queues, we are currently developing an efficient packet drop policy based on objective criteria which will still satisfy the consistency requirement.